本文介绍了如何在 TCP 协议之上,利用 Go 语言实现一个简单的 HTTP 服务器。
首先,新建一个项目,命名为 simple-http-server。通过如下命令创建项目目录,并初始化 Go 模块:
$ mkdir simple-http-server
$ cd simple-http-server
$ go mod init simple-http-server
接下来创建main.go。本地 8080 端口启动 TCP 监听服务。当有新的连接到来时,每个连接均由一个独立的 goroutine 进行处理,从而保证服务器能够并发处理多个请求。
实现HTTP GET方法
监听 TCP 链接
package main
import (
"fmt"
"log"
"net"
)
func main() {
listener, err := net.Listen("tcp", "localhost:8080") // 监听本地 8080 端口
if err != nil {
log.Fatal(err)
}
defer listener.Close()
fmt.Println("Server listening on localhost:8080")
for {
conn, err := listener.Accept()
if err != nil {
log.Println("Error accepting connection:", err)
continue
}
go handleConnection(conn) // 使用 goroutine 处理每个连接
}
}
// handleConnection 用于处理单个连接
func handleConnection(conn net.Conn) {
}
读取 HTTP 请求报文
在建立了基本的 TCP 连接之后,接下来的任务是读取 HTTP 请求报文。在 handleConnection 函数中,将读取客户端发送的请求数据,并简单打印出来。
func handleConnection(conn net.Conn) {
defer conn.Close()
buf := make([]byte, 4096)
n, err := conn.Read(buf)
if err != nil {
log.Println("Error reading from connection:", err)
return
}
request := string(buf[:n])
log.Println("收到请求:\n", request)
}
解析请求行
随后,对 HTTP 请求报文中的请求行进行解析。请求行包含请求方法、路径以及 HTTP 版本号,解析后可打印出各个字段,便于调试和后续处理。
// 按照 HTTP 协议,第一行为请求行,格式为 "METHOD PATH VERSION"
lines := strings.Split(request, "\r\n")
if len(lines) < 1 {
log.Println("无效的 HTTP 请求")
return
}
requestLine := lines[0]
parts := strings.Split(requestLine, " ")
if len(parts) < 3 {
log.Println("无效的 HTTP 请求行")
return
}
method := parts[0]
path := parts[1]
version := parts[2] // 如果需要可以使用
log.Println("方法: ", method, "路径: ", path, "版本: ", version)
返回响应
针对 HTTP 方法的限制,程序仅支持 GET 方法。如果请求的方法非 GET,则返回 405 状态码。否则,构造一个简单的 HTML 响应,将请求的路径在页面中显示出来。响应报文中包括状态行、必要的响应头(如 Content-Length 和 Content-Type)以及响应体内容。
// 这里只支持 GET 方法
if method != "GET" {
response := "HTTP/1.1 405 Method Not Allowed\r\n" +
"Content-Length: 0\r\n" +
"Connection: close\r\n" +
"\r\n"
_, err := conn.Write([]byte(response))
if err != nil {
log.Println("Error writing response:", err)
}
return
}
// 构造响应体
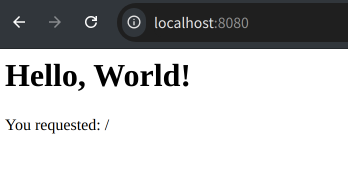
body := fmt.Sprintf("<html><body><h1>Hello, World!</h1><p>You requested: %s</p></body></html>", path)
// 构造 HTTP/1.1 响应
response := "HTTP/1.1 200 OK\r\n"
response += fmt.Sprintf("Content-Length: %d\r\n", len(body))
response += "Content-Type: text/html; charset=utf-8\r\n"
response += "Connection: close\r\n"
response += "\r\n"
response += body
_, err = conn.Write([]byte(response))
if err != nil {
log.Println("Error writing response:", err)
}
运行程序后,如果请求根目录,将会显示一页包含请求路径信息的页面,如下图所示。
通过 HTTP 获取文件
进一步完善程序的功能,使之能够通过 HTTP 获取文件。为此,添加了两个辅助函数。一个辅助函数用于根据文件后缀获取 MIME 类型,另一个辅助函数根据请求路径返回一个 io.Reader。对于根目录的请求,getFile 函数返回一个默认的 HTML 页面,其中包含 “Hello, World!” 与请求路径;对于其它路径,则尝试从当前目录读取对应的文件。
辅助函数 getMimeType 实现如下:
// getMimeType 根据文件后缀返回对应的 MIME 类型
func getMimeType(filename string) string {
ext := filepath.Ext(filename)
mType := mime.TypeByExtension(ext)
if mType == "" {
mType = "application/octet-stream"
}
return mType
}
而 getFile 函数的实现如下所示。getFile 函数对请求路径进行了清理,防止目录穿越攻击,并采用了简单的逻辑判断:当请求根目录时,返回内置的默认页面;否则尝试打开对应的文件并返回文件句柄。
// getFile 根据请求路径返回一个 io.Reader
// 如果路径为根目录,则返回一个包含 "Hello, World!" 及请求路径的 Reader;
// 否则,尝试从当前目录读取对应的文件。
func getFile(path string) io.Reader {
cleanPath := filepath.Clean(path)
// 如果路径为根目录,则返回默认内容
if cleanPath == "/" {
content := fmt.Sprintf("<html><body><h1>Hello, World!</h1><p>You requested: %s</p></body></html>", path)
return strings.NewReader(content)
}
// 拼接当前目录下的文件路径
file, err := os.Open("." + cleanPath)
if err != nil {
log.Println("Error opening file:", err)
return nil
}
return file
}
在修改 handleConnection 函数时,将固定返回的内容替换为通过 getFile 函数获取的文件或默认页面。读取到的内容随后根据文件后缀判断 MIME 类型,并通过构造响应头返回给客户端。此部分代码如下:
// 此处不再修改根路径,直接将 path 传入 getFile 处理
fileReader, mimeType := getFile(path)
if fileReader == nil {
// 文件不存在则返回 404
response := "HTTP/1.1 404 Not Found\r\n" +
"Content-Length: 0\r\n" +
"Connection: close\r\n" +
"\r\n"
_, _ = conn.Write([]byte(response))
return
}
// 读取文件或默认内容
content, err := io.ReadAll(fileReader)
if err != nil {
log.Println("Error reading content:", err)
response := "HTTP/1.1 500 Internal Server Error\r\n" +
"Content-Length: 0\r\n" +
"Connection: close\r\n" +
"\r\n"
_, _ = conn.Write([]byte(response))
return
}
header := fmt.Sprintf("HTTP/1.1 200 OK\r\nContent-Length: %d\r\nContent-Type: %s\r\nConnection: close\r\n\r\n", len(content), mimeType)
_, err = conn.Write([]byte(header))
if err != nil {
log.Println("Error writing header:", err)
return
}
_, err = conn.Write(content)
if err != nil {
log.Println("Error writing content:", err)
return
}
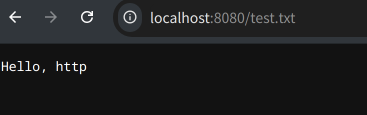
在工作目录下放置一个test.txt文件
$ echo "Hello, http" > test.txt
运行程序后,通过浏览器访问相应文件路径即可看到 test.txt 文件的内容。效果如下图所示。
HTTP 文件目录服务器
进一步扩展程序功能,实现 HTTP 文件目录服务器。该功能允许通过浏览器浏览指定工作目录下的所有文件,并支持点击目录项进入子目录或下载文件。首先引入命令行选项,指定服务器使用的工作目录。为此,声明了一个全局变量 rootDir,并在 init 函数中通过 flag 包绑定了 -d 参数,默认工作目录为当前目录。在 main 函数开头调用 flag.Parse() 解析命令行参数。
指定工作目录
指定工作目录
声明全局变量rootDir以及init()函数
var rootDir string
func init() {
flag.StringVar(&rootDir, "d", ".", "设置工作目录")
}
并在main函数的开头添加 flag.Parse()
func main() {
flag.Parse()
// 后续代码...
}
通过模板生成 HTML 页面
目录页面的生成依赖于 HTML 模板和两个辅助函数。首先定义一个 HTML 模板,该模板展示当前目录路径和目录项列表。模板中利用了数据填充语法来生成目录列表页面。
const templateStr = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Directory Listing of {{.CurrentPath}}</title>
</head>
<body>
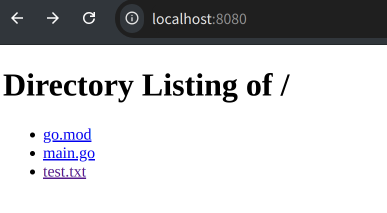
<h1>Directory Listing of {{.CurrentPath}}</h1>
<ul>
{{range .Entries}}
<li><a href="{{.URL}}">{{.Name}}</a></li>
{{end}}
</ul>
</body>
</html>
`
随后通过 os.ReadDir 函数获取指定目录下的所有条目,生成每个目录项对应的名称与 URL。目录项数据结构定义为 DirEntry,辅助函数 listDirectoryEntries 负责读取目录并构造目录项列表:
type DirEntry struct {
Name string
URL string
}
func listDirectoryEntries(dirPath, currentURL string) ([]DirEntry, error) {
entries, err := os.ReadDir(dirPath)
if err != nil {
return nil, err
}
var result []DirEntry
for _, entry := range entries {
name := entry.Name()
url := filepath.Join(currentURL, name)
if entry.IsDir() {
url += "/" // 目录末尾加斜杠,便于区分
}
result = append(result, DirEntry{
Name: name,
URL: url,
})
}
return result, nil
}
利用模板生成目录页面的函数 generateDirectoryPage 接受文件系统中的绝对目录路径以及当前请求的 URL。该函数调用 listDirectoryEntries 获取目录项列表,然后通过 text/template 包将数据填充至 HTML 模板中,并将生成的页面作为 io.Reader 返回。
type DirListingData struct {
CurrentPath string
Entries []DirEntry
}
func generateDirectoryPage(fsDir, currentURL string) io.Reader {
entries, err := listDirectoryEntries(fsDir, currentURL)
if err != nil {
// 出错时可以生成一个简单的错误页面
return strings.NewReader("Error reading directory")
}
data := DirListingData{
CurrentPath: currentURL,
Entries: entries,
}
// 假设 templateStr 是上面给出的模板内容
tmpl, err := template.New("dirList").Parse(templateStr)
if err != nil {
log.Println("Template parse error:", err)
return strings.NewReader("Template error")
}
var buf bytes.Buffer
err = tmpl.Execute(&buf, data)
if err != nil {
log.Println("Template execution error:", err)
return strings.NewReader("Error generating page")
}
return &buf
}
最后,修改 getFile 函数使其支持目录请求。当传入路径对应于目录时,通过 os.Stat 判断后调用 generateDirectoryPage 生成目录列表页面;否则正常打开文件返回文件。
func getFile(path string) (io.Reader, string) {
// 清理路径并拼接到根目录(假设 rootDir 已定义)
cleanPath := filepath.Clean(path)
fullPath := filepath.Join(rootDir, cleanPath)
// 判断路径是否存在以及是文件还是目录
info, err := os.Stat(fullPath)
if err != nil {
log.Println("Error stating path:", err)
return nil, ""
}
// 如果是目录,则生成目录列表页面,MIME 类型固定为 text/html
if info.IsDir() {
return generateDirectoryPage(fullPath, cleanPath), "text/html"
}
// 否则,打开文件
file, err := os.Open(fullPath)
if err != nil {
log.Println("Error opening file:", err)
return nil, ""
}
// 使用 getMimeType 获取 MIME 类型
mimeType := getMimeType(fullPath)
return file, mimeType
}
运行程序后,将会看到根目录下的所有文件和目录以列表方式展示,点击目录项可进入子目录或下载文件。
实现 Keep-alive
修改并拆分handleConnection
将原来handleConnection的功能移动到辅助processHTTPRequest中
func processHTTPRequest(conn net.Conn, req *HTTPRequest, keepAlive bool) error {
// 这里只处理 GET 方法,其他方法可返回 405
if req.Method != "GET" {
resp := "HTTP/1.1 405 Method Not Allowed\r\nContent-Length: 0\r\nConnection: close\r\n\r\n"
_, err := conn.Write([]byte(resp))
return err
}
// 调用 getFile,根据请求路径获取内容和 MIME 类型
reader, mimeType := getFile(req.Path)
if reader == nil {
// 返回 404 页面
resp := "HTTP/1.1 404 Not Found\r\nContent-Length: 0\r\nConnection: close\r\n\r\n"
_, err := conn.Write([]byte(resp))
return err
}
content, err := io.ReadAll(reader)
if err != nil {
resp := "HTTP/1.1 500 Internal Server Error\r\nContent-Length: 0\r\nConnection: close\r\n\r\n"
_, err = conn.Write([]byte(resp))
return err
}
// 构造响应头,根据 keep-alive 状态设置 Connection 头
header := fmt.Sprintf("HTTP/1.1 200 OK\r\nContent-Length: %d\r\nContent-Type: %s\r\n", len(content), mimeType)
if keepAlive {
header += "Connection: keep-alive\r\n\r\n"
} else {
header += "Connection: close\r\n\r\n"
}
if _, err = conn.Write([]byte(header)); err != nil {
return err
}
if _, err = conn.Write(content); err != nil {
return err
}
return nil
}
在handleConnection中只留下最基本的处理逻辑
func handleConnection(conn net.Conn) {
defer conn.Close()
// 循环处理多个请求
for {
// 设置读取超时,防止空闲连接占用资源
conn.SetReadDeadline(time.Now().Add(30 * time.Second))
req, err := readHTTPRequest(conn)
if err != nil {
// 超时或读取错误时退出循环
log.Println("Error reading HTTP request:", err)
break
}
// 判断是否需要保持连接
keepAlive := shouldKeepAlive(req)
// 处理请求并写入响应
if err := processHTTPRequest(conn, req, keepAlive); err != nil {
log.Println("Error processing request:", err)
break
}
// 如果此次请求要求关闭连接,则退出循环
if !keepAlive {
break
}
}
}
读取并解析HTTP请求的辅助函数readHTTPRequest
type HTTPRequest struct {
Method string
Path string
Version string
Headers map[string]string
}
func readHTTPRequest(conn net.Conn) (*HTTPRequest, error) {
reader := bufio.NewReader(conn)
// 读取请求行,例如 "GET /path HTTP/1.1"
line, err := reader.ReadString('\n')
if err != nil {
return nil, err
}
line = strings.TrimSpace(line)
parts := strings.Split(line, " ")
if len(parts) < 3 {
return nil, fmt.Errorf("invalid request line")
}
req := &HTTPRequest{
Method: parts[0],
Path: parts[1],
Version: parts[2],
Headers: make(map[string]string),
}
// 读取所有请求头,直到遇到空行
for {
headerLine, err := reader.ReadString('\n')
if err != nil {
return nil, err
}
headerLine = strings.TrimSpace(headerLine)
if headerLine == "" {
break // 空行表示请求头结束
}
headerParts := strings.SplitN(headerLine, ":", 2)
if len(headerParts) == 2 {
key := strings.ToLower(strings.TrimSpace(headerParts[0]))
value := strings.TrimSpace(headerParts[1])
req.Headers[key] = value
}
}
return req, nil
}
辅助函数shouldKeepAlive,判断是否保持连接
func shouldKeepAlive(req *HTTPRequest) bool {
// 默认 HTTP/1.1 连接保持,HTTP/1.0 默认不保持
connectionHeader, exists := req.Headers["connection"]
if req.Version == "HTTP/1.1" {
// HTTP/1.1 默认 keep-alive,除非明确写了 "close"
if exists && strings.ToLower(connectionHeader) == "close" {
return false
}
return true
} else if req.Version == "HTTP/1.0" {
// HTTP/1.0 默认关闭,除非明确指定 "keep-alive"
if exists && strings.ToLower(connectionHeader) == "keep-alive" {
return true
}
return false
}
return false
}
使用curl对keep-alive进行测试,可以看到Content: keep-alive出现在报文中,并且在一个TCP连接中提交了两个HTTP请求。
$ curl -v http://localhost:8080/ --next http://localhost:8080/test.txt
* Host localhost:8080 was resolved.
* IPv6: ::1
* IPv4: 127.0.0.1
* Trying [::1]:8080...
* connect to ::1 port 8080 from ::1 port 59320 failed: Connection refused
* Trying 127.0.0.1:8080...
* Connected to localhost (127.0.0.1) port 8080
* using HTTP/1.x
> GET / HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/8.12.0
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< Content-Length: 378
< Content-Type: text/html
< Connection: keep-alive
<
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Directory Listing of /</title>
</head>
<body>
<h1>Directory Listing of /</h1>
<ul>
<li><a href="/go.mod">go.mod</a></li>
<li><a href="/main.go">main.go</a></li>
<li><a href="/test.txt">test.txt</a></li>
</ul>
</body>
</html>
* Connection #0 to host localhost left intact
* Re-using existing connection with host localhost
> GET /test.txt HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/8.12.0
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< Content-Length: 12
< Content-Type: text/plain; charset=utf-8
< Connection: keep-alive
<
Hello, http
* Connection #0 to host localhost left intact
支持 Content-Range 头部字段
首先,修改 getFile 函数,使其返回一个实现了 io.ReadSeeker 接口的对象和 MIME 类型。这一步保证了在处理范围请求时,可以调用 Seek 定位到文件中指定的位置。
func getFile(path string) (io.ReadSeeker, string) {
cleanPath := filepath.Clean(path)
fullPath := filepath.Join(rootDir, cleanPath)
info, err := os.Stat(fullPath)
if err != nil {
log.Println("Error stating path:", err)
return nil, ""
}
// 如果是目录,则生成目录列表页面,返回一个 strings.Reader(虽然它不支持 Seek,但目录请求通常不支持范围请求)
if info.IsDir() {
reader := generateDirectoryPage(fullPath, cleanPath) // 生成目录 HTML 页面
return reader, "text/html"
}
file, err := os.Open(fullPath) // *os.File 实现了 io.ReadSeeker
if err != nil {
log.Println("Error opening file:", err)
return nil, ""
}
mimeType := getMimeType(fullPath)
return file, mimeType
}
添加辅助函数 parseRangeHeader,用于解析请求头中的 Range 值。该函数支持解析形如 bytes=START-END(或者后缀形式如 bytes=-N)的格式,并根据资源的总大小计算出实际的起始和结束位置。
func parseRangeHeader(rangeHeader string, fileSize int64) (start, end int64, err error) {
// 假设格式为 "bytes=start-end"
const prefix = "bytes="
if !strings.HasPrefix(rangeHeader, prefix) {
return 0, 0, fmt.Errorf("invalid range header")
}
spec := strings.TrimPrefix(rangeHeader, prefix)
parts := strings.Split(spec, "-")
if len(parts) != 2 {
return 0, 0, fmt.Errorf("invalid range spec")
}
if parts[0] == "" { // 后缀范围,如 "-500"
suffix, err := strconv.ParseInt(parts[1], 10, 64)
if err != nil {
return 0, 0, err
}
if suffix > fileSize {
suffix = fileSize
}
return fileSize - suffix, fileSize - 1, nil
}
// 解析起始位置
start, err = strconv.ParseInt(parts[0], 10, 64)
if err != nil {
return 0, 0, err
}
if parts[1] != "" {
end, err = strconv.ParseInt(parts[1], 10, 64)
if err != nil {
return 0, 0, err
}
} else {
end = fileSize - 1
}
if start > end || end >= fileSize {
return 0, 0, fmt.Errorf("invalid range: start=%d, end=%d, fileSize=%d", start, end, fileSize)
}
return start, end, nil
}
在 processHTTPRequest 函数中,首先检查请求头中是否包含 Range 字段。如果存在,就不读取整个内容,而是调用新的辅助函数 handleRangeRequest。
handleRangeRequest 首先定位到文件中 Range 请求指定的位置(调用 Seek),然后读取所请求范围内的内容。根据是否需要保持连接(keep-alive),构造正确的响应头和状态码,再将数据发送给客户端。
func handleRangeRequest(conn net.Conn, req *HTTPRequest, rs io.ReadSeeker, mimeType string, keepAlive bool) error {
file, ok := rs.(*os.File)
if !ok {
resp := "HTTP/1.1 416 Range Not Satisfiable\r\nContent-Length: 0\r\nConnection: close\r\n\r\n"
conn.Write([]byte(resp))
return fmt.Errorf("range request not supported")
}
fi, err := file.Stat()
if err != nil {
return err
}
fileSize := fi.Size()
rangeHeader := req.Headers["range"]
start, end, err := parseRangeHeader(rangeHeader, fileSize)
if err != nil {
resp := "HTTP/1.1 416 Range Not Satisfiable\r\nContent-Length: 0\r\nConnection: close\r\n\r\n"
conn.Write([]byte(resp))
return err
}
length := end - start + 1
_, err = rs.Seek(start, io.SeekStart)
if err != nil {
return err
}
content := make([]byte, length)
n, err := io.ReadFull(rs, content)
if err != nil || int64(n) != length {
return fmt.Errorf("failed to read requested range")
}
connState := "keep-alive"
if !keepAlive {
connState = "close"
}
header := fmt.Sprintf("HTTP/1.1 206 Partial Content\r\nContent-Length: %d\r\nContent-Type: %s\r\n",
len(content), mimeType)
header += fmt.Sprintf("Content-Range: bytes %d-%d/%d\r\nConnection: %s\r\n\r\n",
start, end, fileSize, connState)
conn.Write([]byte(header))
conn.Write(content)
return nil
}
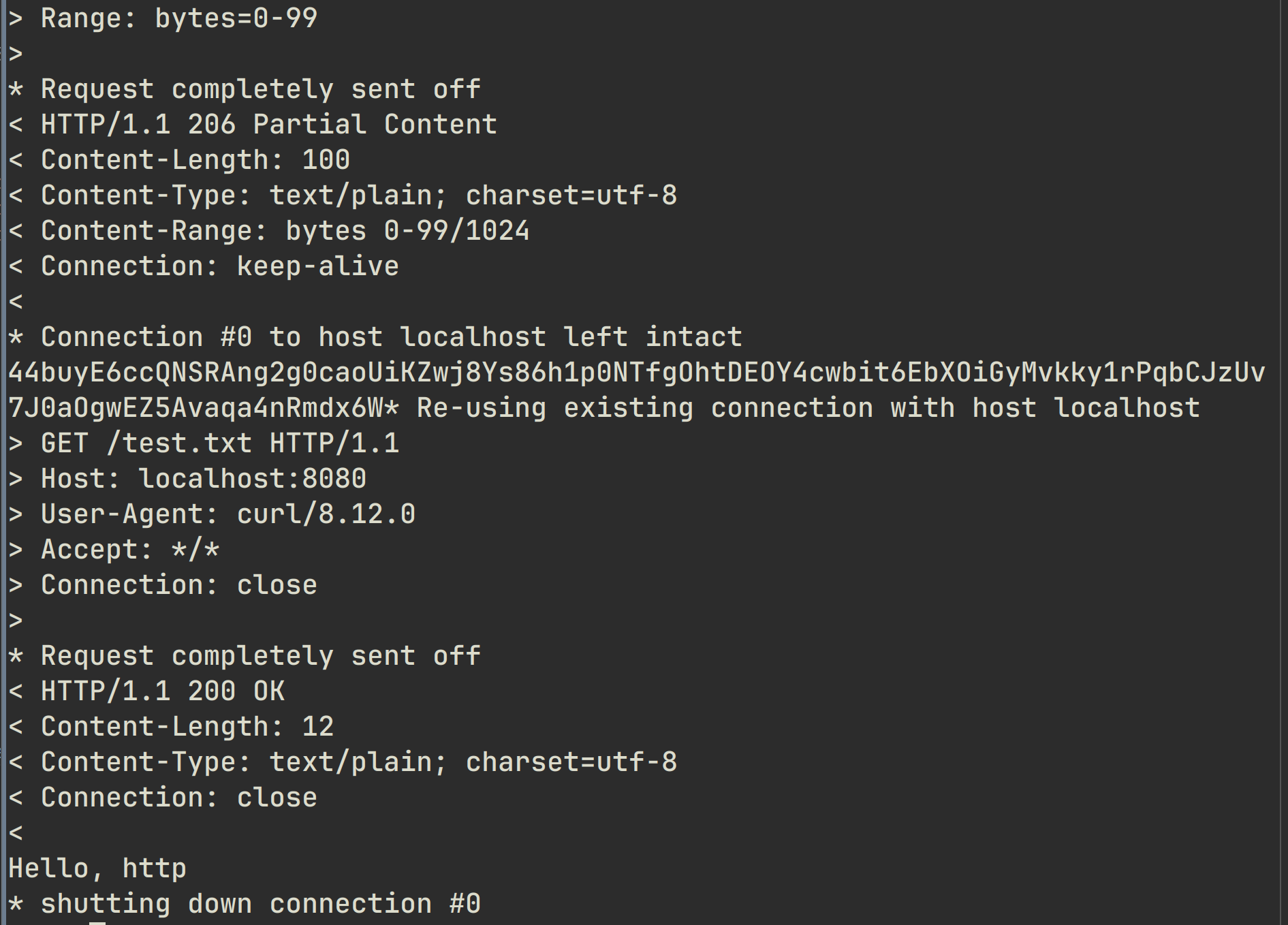
使用curl进行测试
$ curl -v --header "Range: bytes=0-3" http://localhost:8080/random.txt --next --header "Connection: close" http://localhost:8080/test.txt
* Host localhost:8080 was resolved.
* IPv6: ::1
* IPv4: 127.0.0.1
* Trying [::1]:8080...
* connect to ::1 port 8080 from ::1 port 49028 failed: Connection refused
* Trying 127.0.0.1:8080...
* Connected to localhost (127.0.0.1) port 8080
* using HTTP/1.x
> GET /random.txt HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/8.12.0
> Accept: */*
> Range: bytes=0-3
>
* Request completely sent off
< HTTP/1.1 206 Partial Content
< Content-Length: 4
< Content-Type: text/plain; charset=utf-8
< Content-Range: bytes 0-3/1024
< Connection: keep-alive
<
* Connection #0 to host localhost left intact
5Nbc* Re-using existing connection with host localhost
> GET /test.txt HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/8.12.0
> Accept: */*
> Connection: close
>
* Request completely sent off
< HTTP/1.1 200 OK
< Content-Length: 12
< Content-Type: text/plain; charset=utf-8
< Connection: close
<
Hello, http
* shutting down connection #0