搭建一个简单的Rag系统
LLM的广泛使用使得快速地为项目编写文档成为可能,恰巧最近想为自己的服务器以及项目编写文档,便于未来对于系统和程序进行持续地维护,然后又转念一想,为什么不再搭建一个RAG系统来与文档进行交互呢?
简介
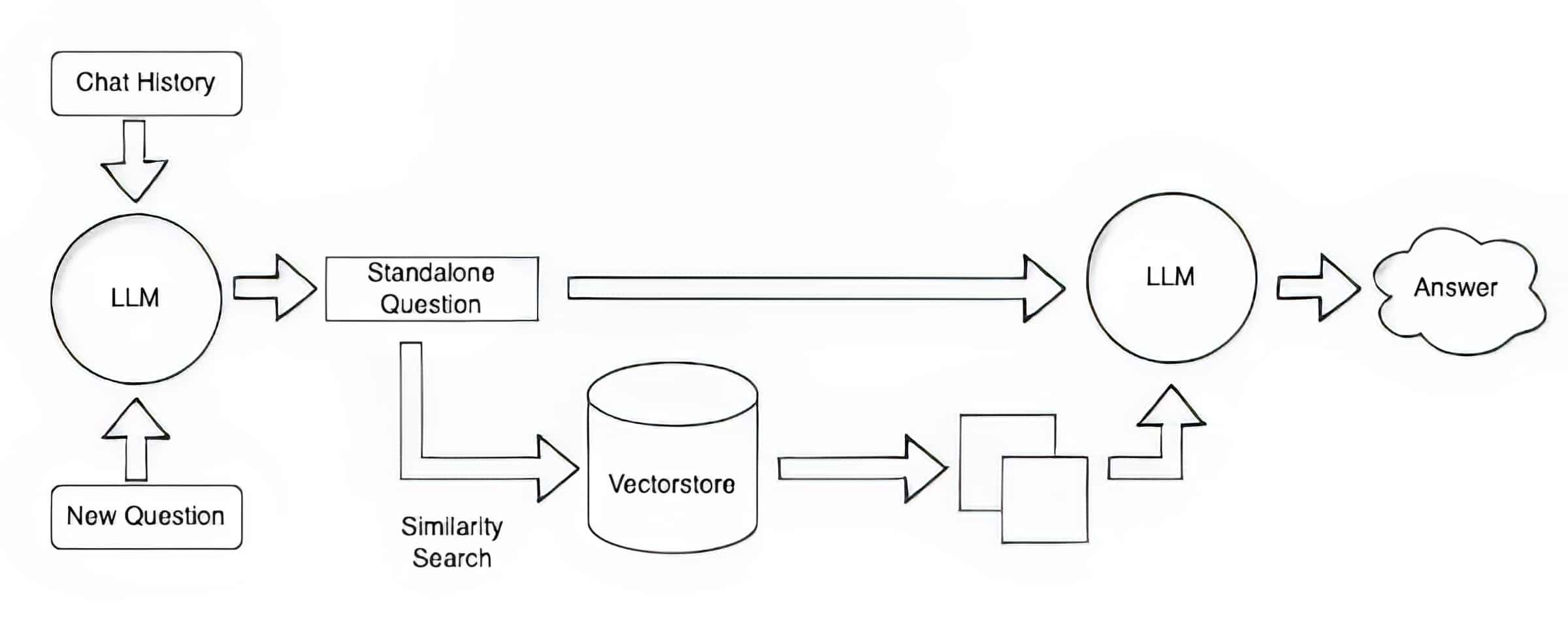
RAG(Retrieval-Augmented Generation)一般用于对于长文档或者知识库的检索,针对用户的prompt,获取其他有关的信息,并附加在正文的后面,再提交给LLM。本文演示的是对于长文本的索引。 搭建一个RAG系统需要以下的部分:
- 语言模型LLM,用于处理prompt。
- RAG Pipeline: 包含文本分割,创建Embedding,合并prompt等操作。
- 向量数据库,存储所需的数据,并用Embedding对其进行索引,并且在用户请求时计算获取最符合要求的记录。
- 文档或者知识库
前置步骤
获取gemini的api key
Gemini是Google的招牌模型,能够免费使用,并且可以在google ai studio获取到api key,
进入google ai studio,点击Get API Key
接着点击Create API Key创建API key,接下来就可以在Python中通过api调用gemini了。
获取文档
将wikipedia “汉语” 词条作为测试,通过python wikipedia包来获取其内容
import wikipedia
def get_wikipedia_page_content(page_title: str, language_code: str) -> str:
wikipedia.set_lang(language_code) # Set the desired language
page = wikipedia.page(page_title)
return page.content
page_title = "汉语"
content = get_wikipedia_page_content(page_title, "zh")
输出结果:
漢語又稱華語,是来自汉民族的语言。汉语拥有声调,是分析语。
汉语是汉藏语系中最大的一支语族,若把整个汉语族視為單一語言,则汉语为世界上母语使用者人数最多的语言,目前全世界有五分之一人口将其作为母語或第二語言。此外,漢語是中华人民共和国、中華民國和新加坡共和國的官方语言,也是海外华人地区、果敢族、东干族和塔兹族等少数民族社区的通用语,也是多个国家官方承认的少数民族语言,在国际事务上是联合国官方语言之一,並被上海合作组织、金砖国家等國際組織採用為官方工作语言。
......
搭建RAG系统
文本分割
用langchain对文本进行分割,使每个chunk的大小不超过500
# 文本分割
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)
chunks = text_splitter.split_text(content)
print(f'Chunks length: {len(chunks)}')
print(chunks[0])
输出
chunks: 56
漢語又稱華語,是来自汉民族的语言。汉语拥有声调,是分析语。
汉语是汉藏语系中最大的一支语族,若把整个汉语族視為單一語言,则汉语为世界上母语使用者人数最多的语言,目前全世界有五分之一人口将其作为母語或第二語言。此外,漢語是中华人民共和国、中華民國和新加坡共和國的官方语言,也是海外华人地区、果敢族、东干族和塔兹族等少数民族社区的通用语,也是多个国家官方承认的少数民族语言,在国际事务上是联合国官方语言之一,並被上海合作组织、金砖国家等國際組織採用為官方工作语言。
漢語在以其為母語的地区有不同通稱,且有多種方言变体,其中以中国北方汉语为基础的北京官話最為流行,其衍生而來的現代標準漢語(有國語、普通話、新加坡标准华语等變體)是漢語圈的主要通用语。在许多语境中,所谓“汉语”实际上指现代标准汉语。
创建embedding
使用sentence transformer来为每一个chunk都创建embedding
# 构建索引
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
chunks_2 = chunks
embeddings = model.encode(chunks)
print(f"Embeddings shape: {embeddings.shape}")
输出:
Embeddings shape: (56, 384)
向量存储
Faiss是一个内存向量存储,支持各种类型的向量索引方式。但是在面向生产环境的部署中,会使用向量数据库如milvus。
将embedding存入faiss,并创建一个函数用于搜索最相近的K个结果,这里用欧几里得距离来衡量句子的相似性。
import faiss
d = embeddings.shape[1]
index = faiss.IndexFlatL2(d)
index.add(embeddings)
helper function:
def get_familiar(query, k=5):
query_embedding = model.encode([query])
k = 5
distances, indices = index.search(query_embedding, k)
result = []
for i, idx in enumerate(indices[0]):
result.append(chunks[idx])
return result
创建用户prompt
将get_familiar获取到的结果拼接到用户prompt的后面
def create_prompt(query, context):
prompt = "Question: " + user_query + "\n" + "Contexts: " + "\n"
for context in rag_context:
prompt = prompt + "[context]" + context + "\n"
return prompt
连接gemini
设置api key,选择模型
import google.generativeai as genai
api_key = os.environ['GOOGLE_API_KEY']
genai.configure(api_key=api_key)
gemini_model = genai.GenerativeModel(
"models/gemini-exp-1206",
system_instruction="你是一个乐于助人的助手,按照给出的context来回答问题"
)
还可以通过以下代码列出所有模型
for m in genai.list_models():
if "generateContent" in m.supported_generation_methods:
print(m.name)
输出:
models/gemini-1.0-pro-latest
models/gemini-1.0-pro
models/gemini-pro
......
进行提问
user_query = "我想要了解一些关于吴语的知识"
rag_context = get_familiar(user_query, 5)
prompt = create_prompt(user_query, rag_context)
response = gemini_model.generate_content(prompt)
if response:
print(response.text)
输出:
吴语是中国南方的一种汉语方言,在过去,吴语也曾被用来教授中文课。例如在“[context]在過去,則於不同地區,有使用該地主流漢語(例如吳語、客家話等)教授中文課的現象。”这个句子中就提到了吴语。
后记
-
本文所介绍的RAG系统只是一个基于向量索引的简单RAG系统,也没用进行相关性检查,可能会出现获取到无关信息的情况,如果想要更近一步获取到更符合语义的星系,应该使用GraphRAG或混合RAG(同时使用GraphRAG和RAG)。
-
如果需要对支持多模态,比如自动提交图像,可以选择Clip或者其他的embedding模型。
-
RAG系统还有另一种用法,不仅能够用于搭建知识库,可以对于系统日志进行索引,再配合LLM进行流式分析,能够更为主动的了解系统的状态,降低运维的成本,提高可以维护的集群的规模,但是持续使用LLM的成本还是相当高昂的,并且流式分析对于单个设备的性能和集群的规模都有很高的要求,所有笔者认为还需要找到办法来解决这些问题。
有关资源
- langchain文本分割: medium
- gemini api的使用方法: github
- sentence transformer: huggingface
- 使用faiss和sentence transformer来创建索引: stephendiehl
- langchain官方rag教程: langchain
- google ai studio: ai studio